
In today’s digital world, where data has become an integral part of our daily lives. May it be our phone’s microphone, websites, mobile applications, social media, customer feedback, or terms & conditions – we consistently provide “yes” consents, so there is no denying that each individual’s data is collected and further pushed to play a bigger role into the decision-making pipeline of the organizations.
This collected data is extracted from different sources, transformed to be used for analytical purposes, and loaded in another location for storage. There are several tools present in the market that could be used for data manipulation. In the next sections, we will delve into some of the top tools used in the market and dissect the information to understand the dynamics of this subject.
Architecture Overview
While researching for top tools, here are a few names that made it to the top of my list – Snowflake, Apache Kafka, Apache Airflow, Tableau, Databricks, Redshift, Bigquery, etc. Let’s dive into their architecture in the following sections:
Snowflake
There are several big data tools in the market serving warehousing purposes for storing structured data and acting as a central repository of preprocessed data for analytics and business intelligence. Snowflake is one of the warehouse solutions. What makes Snowflake different from other solutions is that it is a truly self-managed service, with no hardware requirements and it runs completely on cloud infrastructure making it a go-to for the new Cloud era. Snowflake uses virtual computing instances and a storage service for its computing needs. Understanding the tools’ architecture will help us utilize it more efficiently so let’s have a detailed look at the following pointers:
Snowflake consists of three layers, namely Cloud service, query processing, and storage layer. It is deployed on cloud services and is completely managed by Snowflake itself. On the other hand, the computing platform and storage are managed by the cloud service provider. When deployed on AWS it leverages Amazon Elastic Compute Cloud (EC2) instances as compute and s3 as storage, simultaneously when it comes to deploying on Azure it utilizes Azure Data Lake Storage (ADLS) and Azure virtual machines to compute. Along with Google Cloud Platform (GCP), it utilizes Google Cloud Storage and Google Cloud engine.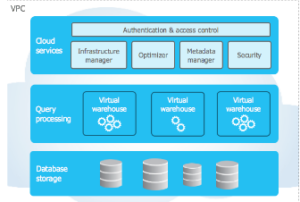
Image credits: Snowflake
Now let’s understand what each layer is responsible for. The Cloud service layer deals with authentication and access control, security, infrastructure management, metadata, and optimizer manager. It is responsible for managing all these features throughout the tool. Query processing is the compute layer where the actual query computation happens and where the cloud compute resources are utilized. Database storage acts as a storage layer for storing the data.
Considering the fact that there are a plethora of big data tools, we don’t shed significant light on the Apache toolkit, this won’t be justice done to their contribution. We all are familiar with Apache tools being widely used in the Data world, so moving on to our next tool Apache Kafka.
Apache Kafka
Apache Kafka deserves an article in itself due to its prominent usage in the industry. It is a distributed data streaming platform that is based on a publish-subscribe messaging system. Let’s check out Kafka components – Producer and Consumer. Producer is any system that produces messages or events in the form of data for further processing for example web-click data, producing orders in e-commerce, System Logs, etc. Next comes the consumer, consumer is any system that consumes data for example Real-time analytics dashboard, consuming orders in an inventory service, etc.
A broker is an intermediate entity that helps in message exchange between consumer and producer, further brokers have divisions as topic and partition. A topic is a common heading given to represent a similar type of data. There can be multiple topics in a cluster. Partition is part of a topic. Partition is data divided into small sub-parts inside the broker and every partition has an offset.
Another important element in Kafka is the ZooKeeper. A ZooKeeper acts as a cluster management system in Kafka. It is used to store information about the Kafka cluster and details of the consumers. It manages brokers by maintaining a list of consumers. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occur, the ZooKeeper sends notifications to Apache Kafka. Zookeeper has a master-slave that handles all the writes, and the rest of the servers are the followers who handle all the reads.
In recent versions of Kafka, it can be used and implemented without Zookeeper too. Furthermore, Apache introduced Kraft which allows Kafka to manage metadata internally without the need for Zookeeper using raft protocol.
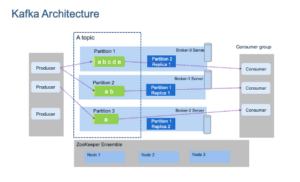
Image credits: Emre Akin
Moving on to the next tool on our list, this is another very popular tool from the Apache toolkit, which we will discuss in the next section.
Apache Airflow
Airflow is a workflow management system that is used to author, schedule, orchestrate, and manage data pipelines and workflows. Airflow organizes your workflows as Directed Acyclic Graph (DAG) which contains individual pieces called tasks. The DAG specifies dependencies between task execution and task describing the actual action that needs to be performed in the task for example fetching data from source, transformations, etc.
Airflow has four main components scheduler, DAG file structure, metadata database, and web server. A scheduler is responsible for triggering the task and also submitting the tasks to the executor to run. A web server is a friendly user interface designed to monitor the workflows that let you trigger and debug the behavior of DAGs and tasks, then we have a DAG file structure that is read by the scheduler for extracting information about what task to execute and when to execute them. A metadata database is used to store the state of workflow and tasks. In summary, A workflow is an entire sequence of tasks and DAG with dependencies defined within airflow, a DAG is the actual data structure used to represent tasks. A task represents a single unit of DAG.
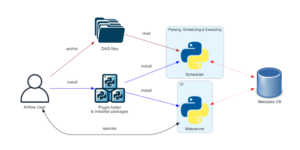 Image credits: Airflow
Image credits: Airflow
As we received brief insights into the top three prominent tools used by the data world, now let’s try to connect the dots and explore the Data story.
Connecting the dots
To understand the data story, we will be taking the example of a use case implemented at Cubera. Cubera is a big data company based in the USA, India, and UAE. The company is creating a Datalake for data repository to be used for analytical purposes from zero-party data sources as directly from data owners. On an average 100 MB of data per day is sourced from various data sources such as mobile phones, browser extensions, host routers, location data both structured and unstructured, etc. Below is the architecture view of the use case.
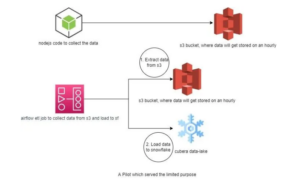
Image credits: Cubera
A node js server is built to collect data streams and pass them to the s3 bucket for storage purposes hourly. While the airflow job is to collect data from the s3 bucket and load it further into Snowflake. However, the above architecture was not cost-efficient due to the following reasons:
- AWS S3 storage cost (for each hour, typically 1 million files are stored).
- Usage costs for ETL running in MWAA (AWS environment).
- The managed instance of Apache Airflow (MWAA).
- Snowflake warehouse cost.
- The data is not real-time, being a drawback.
- The risk of back-filling from a sync-point or a failure point in the Apache airflow job functioning.
The idea is to replace this expensive approach with the most suitable one, here we are replacing s3 as a storage option by constructing a data pipeline using Airflow through Kafka to directly dump data to Snowflake. The following is a newfound approach, as Kafka works on the consumer-producer model, snowflake works as a consumer here. The message gets queued on the Kafka topic from the sourcing server. The Kafka for Snowflake connector subscribes to one or more Kafka topics based on the configuration information provided via the Kafka configuration file.
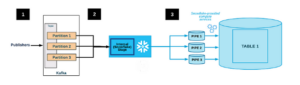
Image credits: Cubera
With around 400 million profile data directly sourced from individual data owners from their personal to household devices as Zero-party data, 2nd Party data from various app partnerships, Cubera Data Lake is continually being refined.
Conclusion
With so many tools available in the market, choosing the right tool is a task. A lot of factors should be taken into consideration before making the right decision, these are some of the factors that will help you in the decision-making – Understanding the data characteristics like what is the volume of data, what type of data we are dealing with – such as structured, unstructured, etc. Anticipating the performance and scalability needs, budget, integration requirements, security, etc.
This is a tedious process and no single tool can fulfill all your data requirements but their desired functionalities can make you lean towards them. As noted earlier, in the above use case budget was a constraint so we moved from the s3 bucket to creating a data pipeline in Airflow. There is no wrong or right answer to which tool is best suited. If we ask the right questions, the tool should give you all the answers.
Join the conversation on IMPAAKT! Share your insights on big data tools and their impact on businesses. Your perspective matters—get involved today!











